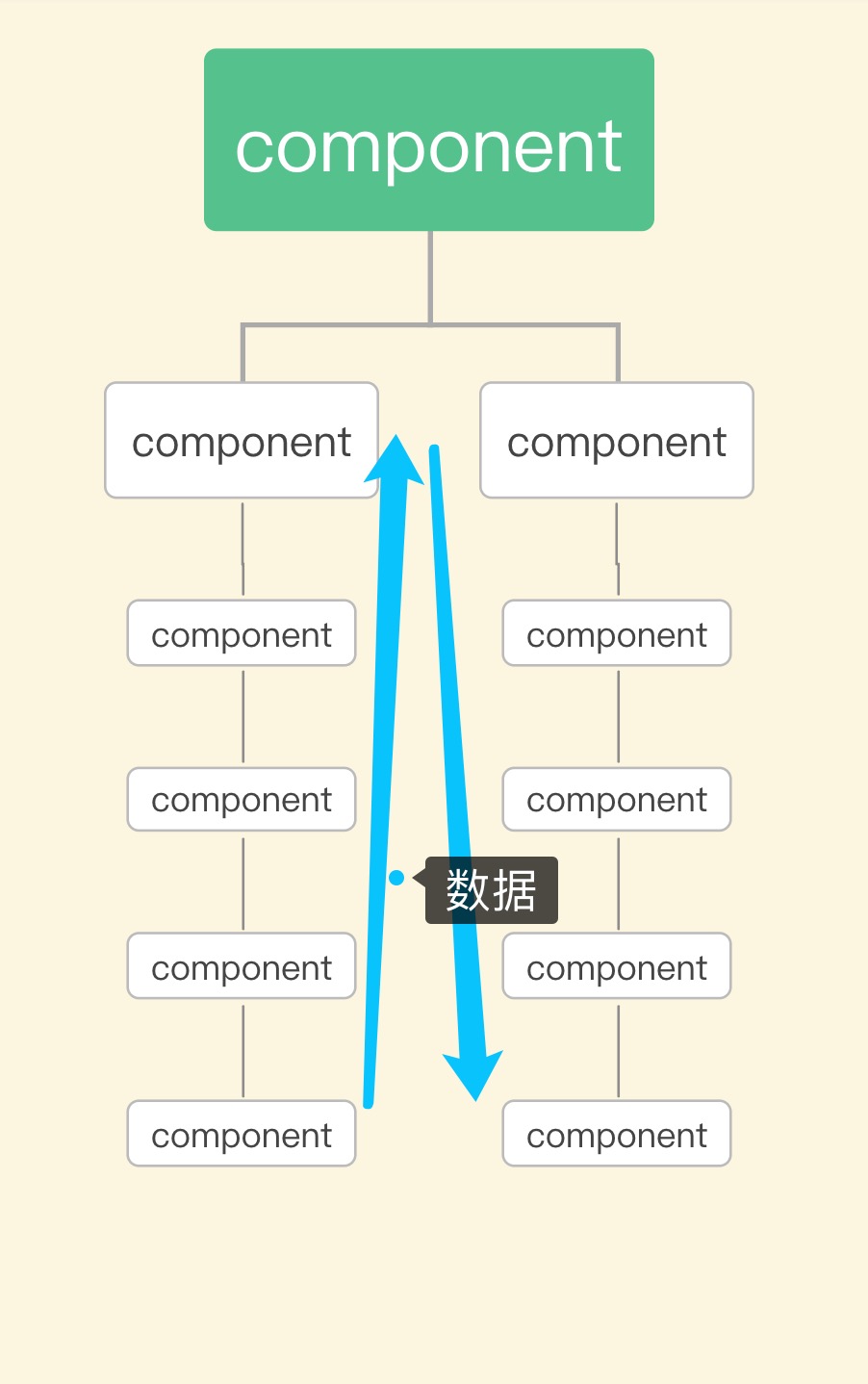
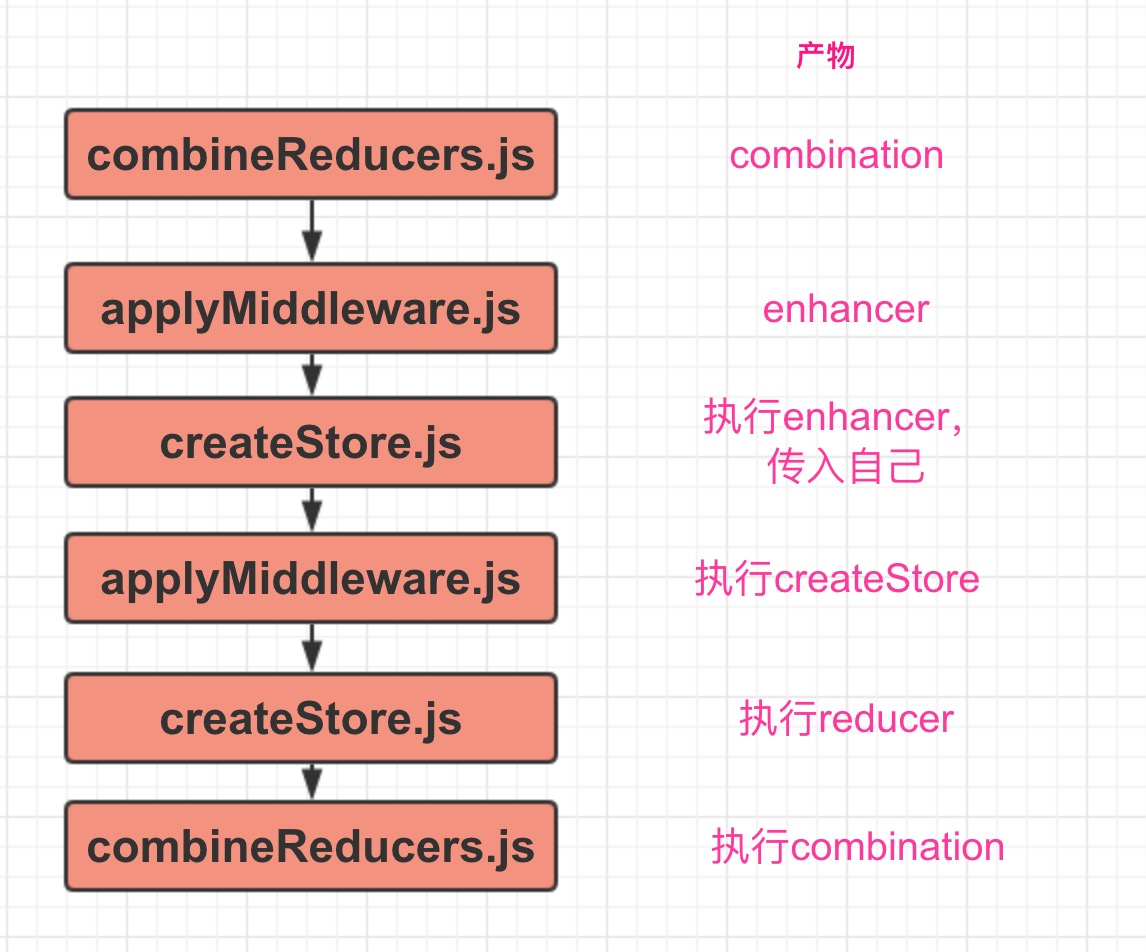
正则表达式
\0,\1,\2 回溯引用
\0 表示整个表达式 \1 代表括号里的子表达式1
2
3const str = 'catcat';
str.match(/(cat)\1/);
// ["catcat", "cat", index: 0, input: "catcat", groups: undefined]
(?: ) 非捕获
1 | const s = 'happy'; |
(?= ) 前向查找
1 | const s = 'happy'; |
(?! ) 前向负查找
1 | const s = 'happy'; |
(?<= ) 后向查找
1 | const s = 'happy'; |
(?<! ) 后向负查找
1 | const s = 'happy'; |